
[Spring] Querydsl 적용하기 - 전체 필터링과 N + 1 문제 해결
이번 포스트에서는 프로젝트의 SQL 쿼리를 리팩토링한 경험을 기록하려고 합니다.
SQL 의 where 절에서 값이 없으면 전체를 반환하는 로직과 고질적인 N + 1 문제를 함께 해결해보려고 합니다.
개발 환경
- Spring Boot 2.4.5
- Gradle 6.8.3
- IntelliJ 2021.1
먼저 해당 프로젝트의 테이블 설계를 간단하게 도식화 한 ERD 입니다.
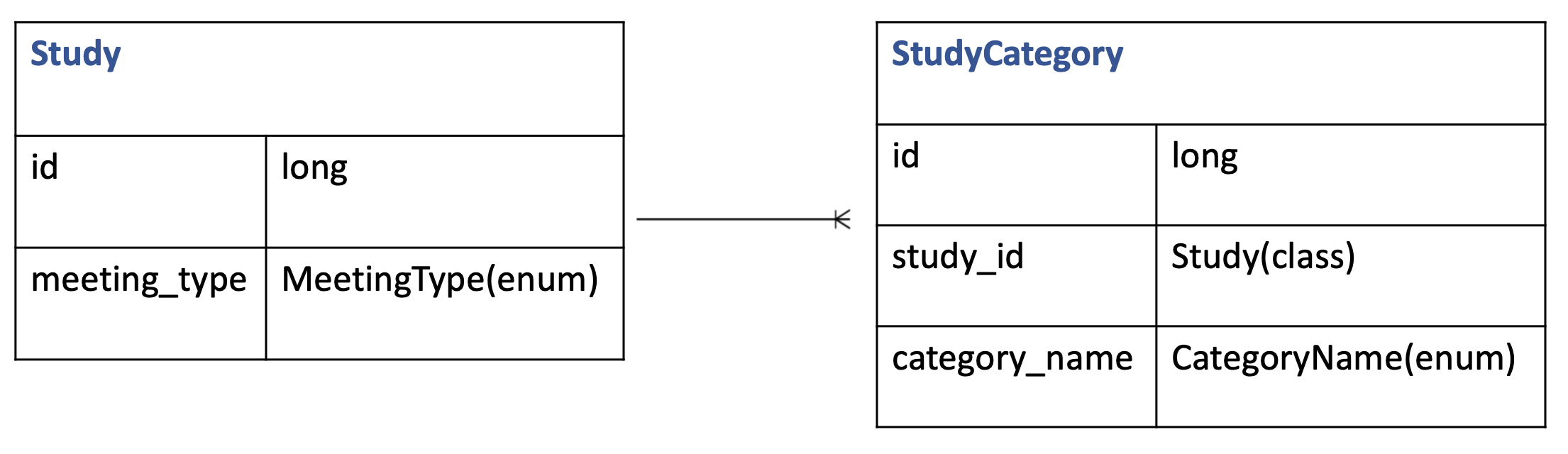
Study 와 StudyCategory 의 관계가 1:N 으로 설정되어 있습니다.
프로젝트의 스터디 필터링을 하는 로직은 Spring Data JPA 쿼리로 짜여져 있었습니다.
그리고 여기서 study 테이블의 meeting_type 속성과 study_category 테이블의 name 을 필터링하는 로직입니다.
문제점
- 필터링할 때 해당 변수 값이 null 이면 전체를 가져와야 하지만 null 인 값만 반환되었습니다.
- in 메소드로 할 수 있었지만 쿼리가 지저분하게 되었습니다.
- 1:N 의 관계에서 N 테이블의 속성을 필터링하기때문에 1 테이블에서 바로 jpa 쿼리로는 찾기가 힘듭니다.
- 따라서 study_category 에서 찾고난 뒤 study 의 속성을 응답 DTO 에 담아야 하기 때문에 참조하는 과정에서 쿼리가 비정상적으로 발생했습니다.
먼저 querydsl 기본 세팅에 대해서 알아보겠습니다.
Gradle 설정
Gradle 과 IntelliJ 가 업데이트 될 때마다 querydsl 을 위해 새로운 설정 방법이 필요합니다.
따라서 Spring 2.4.x, Gradle 6.x 과 intelliJ 2021.x 에 맞는 설정을 맞추기 위해 다음과 같이 설정하였습니다.
def querydslVersion = '4.3.1'
dependencies {
implementation group: 'com.querydsl', name: 'querydsl-jpa', version: querydslVersion
implementation group: 'com.querydsl', name: 'querydsl-apt', version: querydslVersion
implementation group: 'com.querydsl', name: 'querydsl-core', version: querydslVersion
annotationProcessor group: 'com.querydsl', name: 'querydsl-apt', version: querydslVersion
annotationProcessor group: 'com.querydsl', name: 'querydsl-apt', version: querydslVersion, classifier: 'jpa'
annotationProcessor group: 'jakarta.persistence', name: 'jakarta.persistence-api'
annotationProcessor group: 'jakarta.annotation', name: 'jakarta.annotation-api'
}
clean {
delete file('src/main/generated')
}
Config 설정
Gradle 설정이 끝나면 이후에 사용할 쿼리 팩토리를 빈으로 등록해줍니다.
@Configuration
@RequiredArgsConstructor
public class QuerydslConfig {
private final EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}
수정 전 로직
@Service
@RequiredArgsConstructor
public class StudyService {
private final StudyRepository studyRepository;
private final StudyCategoryRepository studyCategoryRepository;
public List<ResponseDto> 수정전_메소드(RequestDto requestDto) {
if (requestDto.getMeetingType() != null) {
if (requestDto.getCategoryName() != null) {
List<StudyCategory> studyCategories = studyCategoryRepository
.findAllByStudy_MeetingTypeAndName(requestDto.getMeetingType(), requestDto.getCategoryName());
return studyCategories.stream().map(studyCategory -> new ResponseDto(studyCategory.getStudy())).collect(Collectors.toList());
} else {
List<Study> studies = studyRepository.findByMeetingType(requestDto.getMeetingType());
return studies.stream().map(ResponseDto::new).collect(Collectors.toList());
}
} else {
if (requestDto.getCategoryName() != null) {
List<StudyCategory> studyCategories = studyCategoryRepository.findAllByName(requestDto.getCategoryName());
return studyCategories.stream().map(StudyCategory::getStudy).map(ResponseDto::new).collect(Collectors.toList());
} else {
List<Study> studies = studyRepository.findAll();
return studies.stream().map(ResponseDto::new).collect(Collectors.toList());
}
}
}
}
- null 인지 아닌지에 따라 분기해서 find 합니다.
- repository 에서 반환되는 List 의 오브젝트가 달라 각각 로직이 서로 다릅니다.
테스트용 데이터를 넣고 각각 조회를 테스트 해보았습니다.
| id | meeting_type |
|---|---|
| 1 | ONLINE |
| 2 | OFFLINE |
| 3 | ONLINE |
| id | study_id | name |
|---|---|---|
| 1 | 1 | INTERVIEW |
| 2 | 2 | IT |
| 3 | 3 | CERTIFICATION |
| 4 | 1 | INTERVIEW |
| 5 | 2 | IT |
| 6 | 3 | CERTIFICATION |
Study 테이블 조회
Hibernate: select study0_.id as id1_0_, study0_.meeting_type as meeting_2_0_ from study study0_
Hibernate: select categories0_.study_id as study_id4_1_0_, categories0_.id as id1_1_0_, categories0_.id as id1_1_1_, categories0_.count as count2_1_1_, categories0_.name as name3_1_1_, categories0_.study_id as study_id4_1_1_ from study_category categories0_ where categories0_.study_id=?
Hibernate: select categories0_.study_id as study_id4_1_0_, categories0_.id as id1_1_0_, categories0_.id as id1_1_1_, categories0_.count as count2_1_1_, categories0_.name as name3_1_1_, categories0_.study_id as study_id4_1_1_ from study_category categories0_ where categories0_.study_id=?
Hibernate: select categories0_.study_id as study_id4_1_0_, categories0_.id as id1_1_0_, categories0_.id as id1_1_1_, categories0_.count as count2_1_1_, categories0_.name as name3_1_1_, categories0_.study_id as study_id4_1_1_ from study_category categories0_ where categories0_.study_id=?
- category name 을 null 로 하여 study 테이블만 조회합니다.
- 다행히?! 쿼리가 find 한번 + 각각의 스터디 n 번 즉, n + 1 만큼 발생하였습니다.
Study_Category 테이블 조회
Hibernate: select studycateg0_.id as id1_1_, studycateg0_.count as count2_1_, studycateg0_.name as name3_1_, studycateg0_.study_id as study_id4_1_ from study_category studycateg0_ left outer join study study1_ on studycateg0_.study_id=study1_.id where study1_.meeting_type=? and studycateg0_.name=?
Hibernate: select study0_.id as id1_0_0_, study0_.meeting_type as meeting_2_0_0_ from study study0_ where study0_.id=?
Hibernate: select categories0_.study_id as study_id4_1_0_, categories0_.id as id1_1_0_, categories0_.id as id1_1_1_, categories0_.count as count2_1_1_, categories0_.name as name3_1_1_, categories0_.study_id as study_id4_1_1_ from study_category categories0_ where categories0_.study_id=?
Hibernate: select study0_.id as id1_0_0_, study0_.meeting_type as meeting_2_0_0_ from study study0_ where study0_.id=?
Hibernate: select categories0_.study_id as study_id4_1_0_, categories0_.id as id1_1_0_, categories0_.id as id1_1_1_, categories0_.count as count2_1_1_, categories0_.name as name3_1_1_, categories0_.study_id as study_id4_1_1_ from study_category categories0_ where categories0_.study_id=?
- category name 에 값을 넣어 study_category 테이블을 조회하고 다시 study 를 참조합니다.
- 그 결과 쿼리가 find 한번 + 각각의 (스터디 카테고리 + 스터디) n * 2 번 즉, 2n + 1 만큼!!!!! 발생하였습니다.
현재도 매우 문제인데 여기서 필터링 할 속성이 하나가 더 추가된다면 if 분기를 8번 해야하고 고질적인 n+1 문제도 변함이 없습니다.
이러한 문제점들 때문에 querydsl 을 이용하여 로직을 새로 짜기로 하였습니다.
Querydsl 로 수정 후 로직
위의 두 가지 문제점을 해결하기 위해 querydsl 을 적용합니다.
서비스 로직
@Service
@RequiredArgsConstructor
public class StudyService {
private final QueryStudyRepository queryStudyRepository;
public List<ResponseDto> getFilteredStudy(RequestDto requestDto) {
List<Study> filteredStudy = queryStudyRepository.getFilteredStudy(requestDto);
return filteredStudy.stream().map(ResponseDto::new).collect(Collectors.toList());
}
}
이전 if 로 복잡했던 로직을 querydsl 로 옮겨 서비스 로직이 매우 간단해진 것을 확인할 수 있습니다.
레포지토리 로직
@Repository
@RequiredArgsConstructor
public class QueryStudyRepository {
private final JPAQueryFactory query; // --- 1
public List<Study> getFilteredStudy(RequestDto requestDto) {
QStudy study = QStudy.study;
QStudyCategory studyCategory = QStudyCategory.studyCategory;
return query
.selectDistinct(study) // --- 2
.from(study)
.leftJoin(study.categories, studyCategory)
.where(eqMeetingType(requestDto.getMeetingType(), study)) // --- 3
.where(eqCategoryName(requestDto.getCategoryName(), studyCategory))
.fetchJoin() // --- 4
.fetch();
}
private Predicate eqCategoryName(CategoryName categoryName, QStudyCategory studyCategory) {
if (categoryName == null) {
return null;
}
return studyCategory.name.eq(categoryName);
}
private Predicate eqMeetingType(MeetingType meetingType, QStudy study) {
if (meetingType == null) {
return null;
}
return study.meetingType.eq(meetingType);
}
}
- 앞서 Config 파일에서 빈으로 등록했던 JPAQueryFactory 를 사용합니다.
- OneToMany 로 조인된 테이블로 인해 중복된 데이터가 조회될 수 있으므로 Distinct 로 가져옵니다.
- where 절로 필터링합니다.
- fetchJoin 메소드로 조인된 테이블도 한번에 가져와 n+1 문제를 해결할 수 있습니다.
조회를 테스트 해보았습니다.
Hibernate: select
distinct
study0_.id as id1_0_0_,
categories1_.id as id1_1_1_,
study0_.meeting_type as meeting_2_0_0_,
categories1_.count as count2_1_1_,
categories1_.name as name3_1_1_,
categories1_.study_id as study_id4_1_1_,
categories1_.study_id as study_id4_1_0__,
categories1_.id as id1_1_0__
from
study study0_
left outer join
study_category categories1_ on study0_.id=categories1_.study_id
- 조회를 할 때 조인된 테이블까지 가져와 쿼리가 한 번만 나가기때문에 N + 1 을 해결할 수 있습니다.
- 필터링할 속성이 더 추가되어도 where 메소드 한 줄만 추가하면 되기때문에 코드가 더욱 간편해졌습니다.
느낀점
이 맛에 리팩토링하나봅니다.
Leave a comment